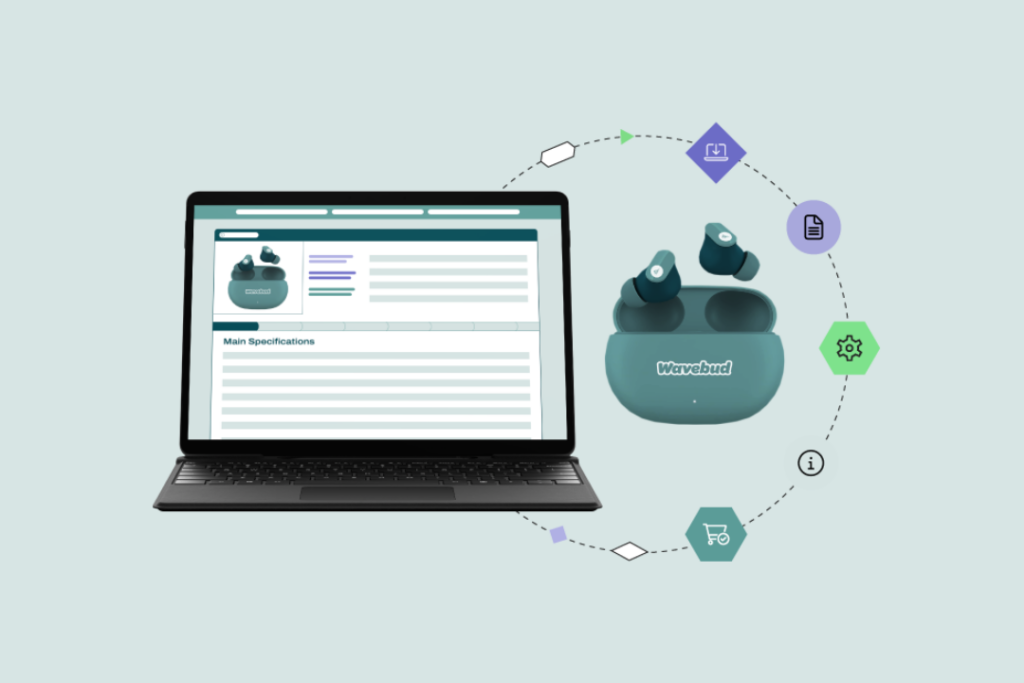
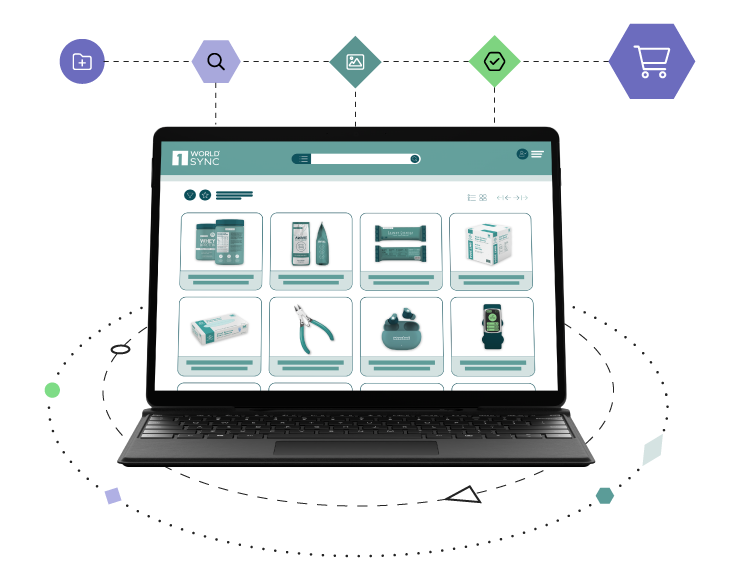
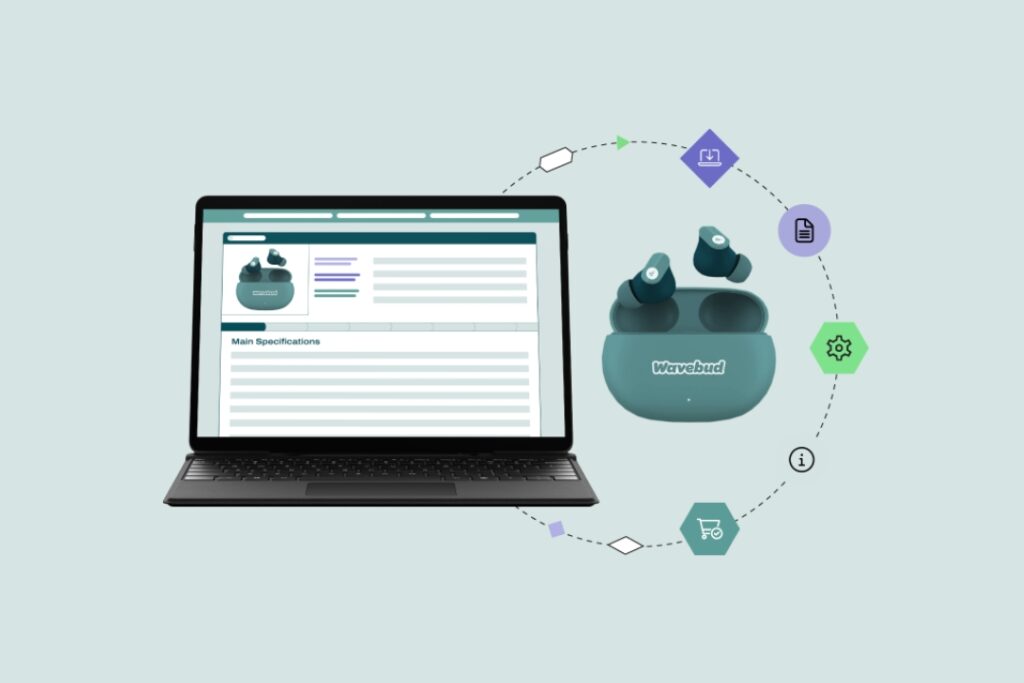
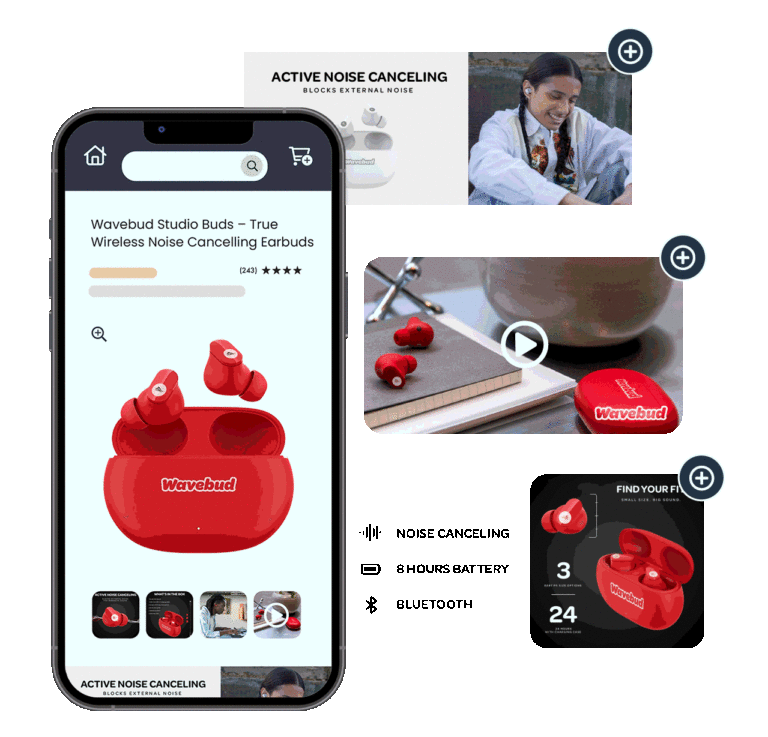
2D Barcodes
How to Prepare for the 2027 2D Barcode Sunrise

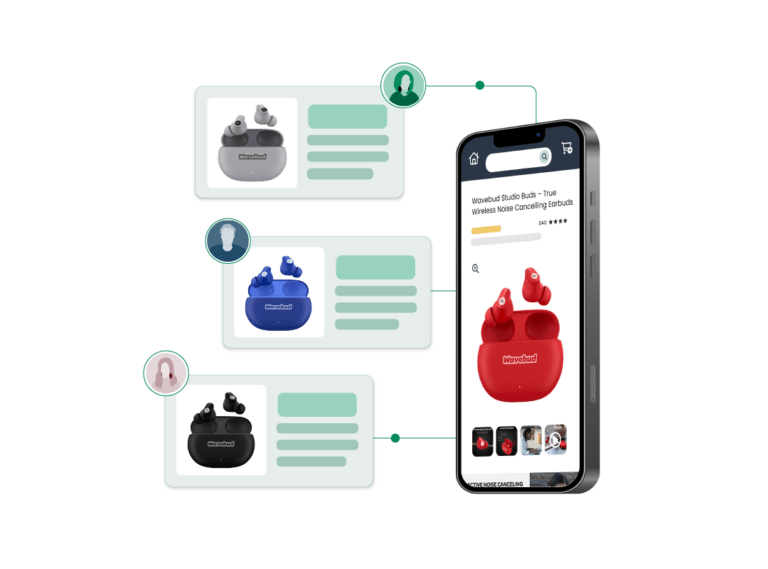
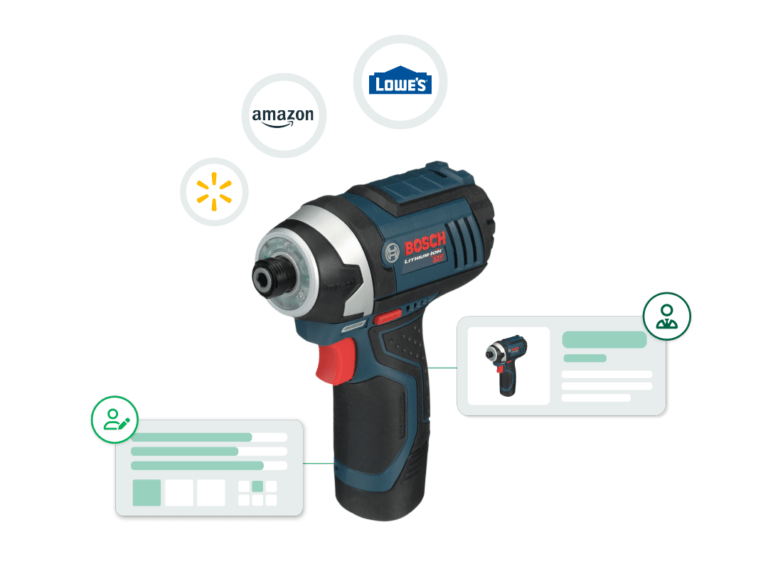
Product Photography
CPG Photography Trends For 2024

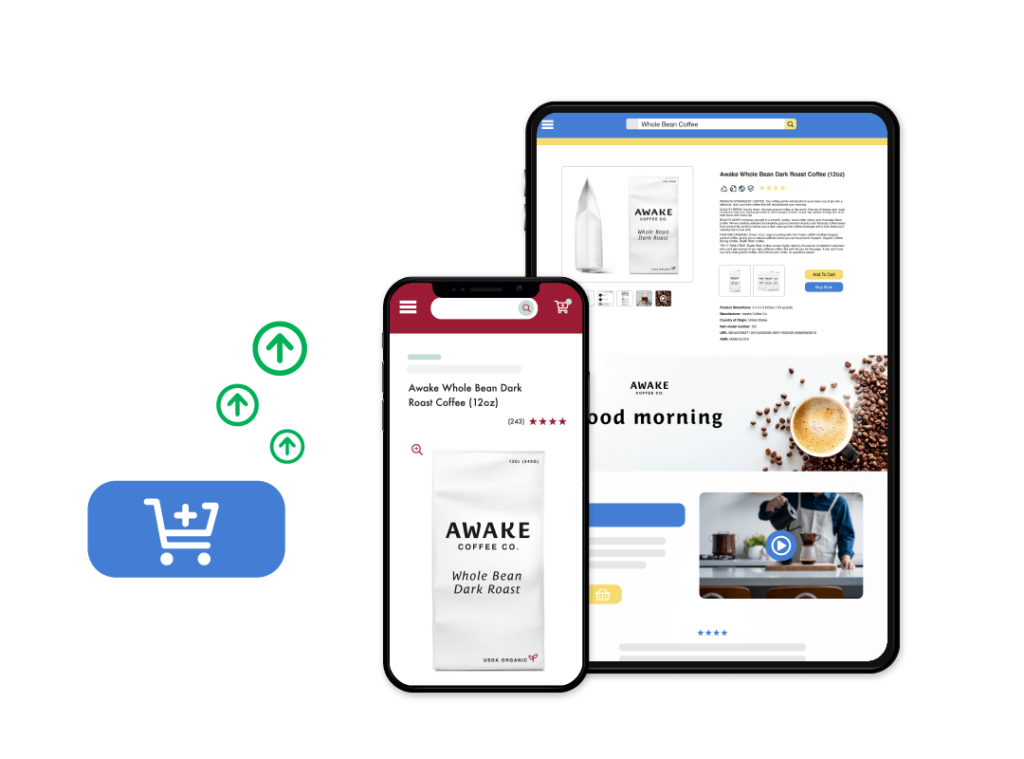
Retail E-Commerce Analytics